Lifelong learning is the main feature that describes myself. I constantly have learning goals that challenge me.
I was born in Queretaro City in 1992.
I studied a bachelor degree in Law and I led an interdisciplinary team that developed a public_policy_model which was presented_to_the_government_of_Queretaro.
I was a government lawyer for 3 years. Then I started studied topics about Equity Research and I_developed_financial_models (DCF) to the valuation of companies listed in the Mexican Stock Exchange.
In 2019 I started studying (on line) a bachelor degree in Mathematics and I discovered my passion for data analysis.
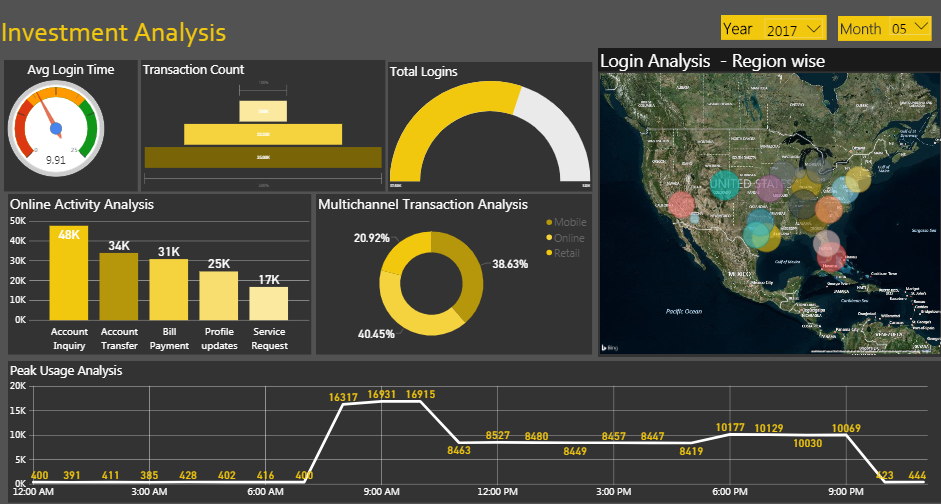
In 2020, I worked at Colliers International like a Market Research Analyst. I managed the databases, created dashboards and quarter reports about the office and industrial real estate market.
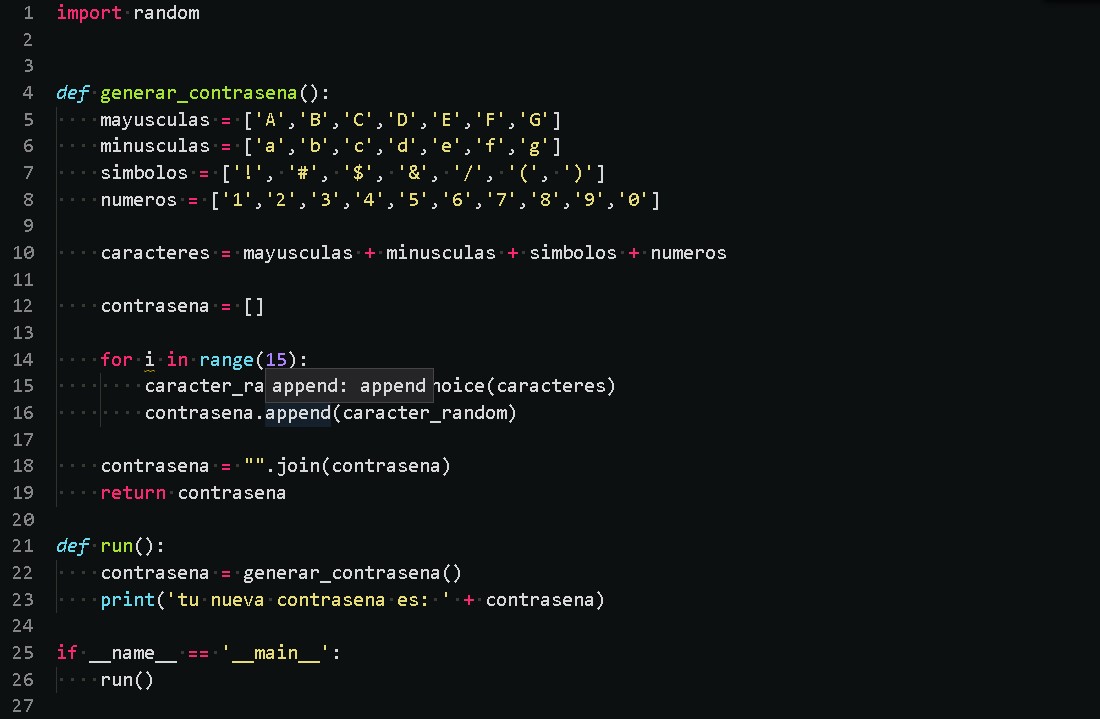
In 2021 I was a Jr Data Architect at Teleperformance Mexico, I created and improved ETL´s with Microsoft data tools (SSIS, Management Studio, JOBS) using SQL and python, and data visualization in Power BI.
Also, in 2021 I started a new position like ETL Developer at Liberty Fianzas, I started with cloud technologies, with AWS I used Glue, CDK projects, S3 and Redshift.
In 2022 I started a Data engineer position at NTT DATA, I started with big data technologies, using Hadoop, spark, pyspark, Hive and using Linux.
I´m also studying at the data engineer path in Platzi
Download_my_CV